ACT: Action Chunking으로 정밀 양팔 조작 — ResNet18·Transformer Decoder·CVAE 완전 분석
비전인코더부터 텐서흐름, 손실함수, Temporal Ensemble까지 — 50개 시연으로 96% 성공률의 비밀
TL;DR
ACT(Action Chunking with Transformers)는 Stanford 연구팀이 2023년 발표한 양팔 로봇 정밀 조작을 위한 모방학습 알고리즘입니다. 핵심 두 가지: (1) Action Chunking — 매 스텝이 아닌 k개 액션을 한 번에 예측해 오차 누적을 k배 줄임, (2) CVAE — 인간 시연의 다양성을 스타일 변수 z로 포착. $20,000짜리 저가형 양팔 로봇 ALOHA 위에서 배터리 삽입, 신발 신기, 지퍼백 닫기 등 6개 정밀 작업에서 80~96% 성공률 달성. 단 50번의 시연(약 10분 데이터)만으로. 이후 ALOHA 2, Mobile ALOHA, ACT+ 등 후속 연구의 기반이 되었고, π0의 Action Chunking 개념도 여기서 출발합니다.
Background: 왜 정밀 양팔 조작이 어려운가
배터리를 정확한 방향으로 삽입하거나, 벨크로를 균일하게 붙이거나, 신발 끈을 묶는 동작 — 인간에게는 쉽지만 로봇에게는 매우 어렵습니다.
왜 어려운가:
- 오차 누적(Compounding Error): 모방학습의 고질병. 스텝 t에서 약간 틀리면 스텝 t+1의 상태가 훈련 분포를 벗어나고, 오차가 기하급수적으로 커짐
- 다중 모드 행동(Multimodal Behavior): 인간이 같은 작업을 여러 방식으로 수행 → 단순 평균은 어느 방법도 아닌 중간값 → 잘못된 정책
- 고주파 정밀 제어: 50Hz 연속 관절 제어 필요 → 이산 토큰 방식 VLA로는 힘듦
- 비싼 하드웨어 장벽: 기존 연구는 수백만 달러짜리 로봇 전제
기존 접근법의 한계:
- BC (Behavior Cloning): 오차 누적에 취약, 정밀 작업에서 0% 성공
- RT-1: 이산 액션 토큰 → 고주파 정밀 제어 어려움
- GAIL/RL: 로봇 환경에서 샘플 효율 낮음, 보상 설계 어려움
ACT의 해결책: Action Chunking + CVAE.
Core Architecture
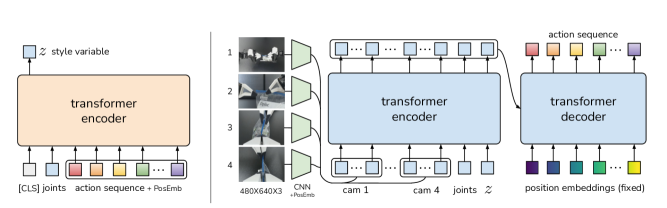 Fig.2. ACT 전체 아키텍처 — CVAE 인코더(훈련 시만 사용) + Vision Encoder + Transformer Encoder/Decoder 정책
Fig.2. ACT 전체 아키텍처 — CVAE 인코더(훈련 시만 사용) + Vision Encoder + Transformer Encoder/Decoder 정책
Vision Encoder: ResNet18 기반 멀티뷰 처리
ACT의 비전 인코더는 ResNet18 (ImageNet pretrained)입니다. SigLIP(OpenVLA/π0)과 다르게 경량 CNN 기반 — 50Hz 실시간 제어에 맞는 선택입니다.
카메라 4개 (고정 2 + 손목 2) → 각각 독립 ResNet18 인코딩
입력: 480×640 RGB 이미지
→ ResNet18 feature extractor
→ Global Average Pooling
→ 512-dim 이미지 특징 벡터 (카메라별)
4개 카메라 출력: [f_cam0 | f_cam1 | f_cam2 | f_cam3]
각 512-dim → concat or positional embedding 추가
왜 SigLIP/ViT가 아닌 ResNet18인가?
| 인코더 | 파라미터 | 추론 속도 | 용도 |
| ResNet18 | 11M | ~3ms/frame | ACT (50Hz 제어) |
| ViT-B/16 | 86M | ~15ms/frame | 고수준 이해 |
| SigLIP-400M | 400M | ~50ms/frame | VLA (OpenVLA, π0) |
50Hz 제어 = 20ms 이내에 전체 추론 완료 필요. ResNet18이 현실적인 선택.
Transformer Encoder: 멀티모달 관측 통합
비전 특징, 관절 정보, 스타일 변수를 하나의 시퀀스로 통합합니다:
토큰 시퀀스 구성:
[z_token] # 스타일 변수 (1개)
[joint_token] # 관절 위치 14-dim → linear projection → d_model
[img_token_0 ... img_token_N] # ResNet18 feature map의 공간 위치별 토큰
→ Positional Embedding 추가
→ Transformer Encoder (표준 BERT 스타일)
- Multi-head Self-Attention
- Feed-Forward Network
- Layer Normalization
→ 출력: 컨텍스트화된 토큰 시퀀스 (메모리)
핵심: 이미지의 어느 위치를 관절의 어느 상태와 연관짓는지를 self-attention이 자동으로 학습.
Transformer Decoder: 액션 청크 생성
k개의 학습 가능한 쿼리 토큰이 액션 시퀀스를 생성합니다:
쿼리 토큰: Q_0, Q_1, ..., Q_{k-1} (각각 d_model dim, 랜덤 초기화 → 학습)
Transformer Decoder (각 레이어):
1. Self-Attention(Q_i, Q_j) # 쿼리들끼리 상호작용 (시간적 일관성)
2. Cross-Attention(Q_i, Memory) # 관측 컨텍스트를 쿼리에 주입
3. FFN + LayerNorm
출력: 각 Q_i → Linear(d_model → 14)
→ â_i = [Δθ_1, ..., Δθ_14] # 14개 관절의 위치 예측
텐서 흐름 전체:
[훈련]
이미지 (4, 3, 480, 640)
└─ ResNet18 × 4 → (4, 512, H', W') → flatten → (N_vis, 512) → (N_vis, d_model)
관절 (14,) → Linear → (1, d_model)
z (d_z,) → Linear → (1, d_model)
시퀀스 = concat([z_token, joint_token, img_tokens]) # (2+N_vis, d_model)
└─ Transformer Encoder → Memory (2+N_vis, d_model)
쿼리 토큰 (k, d_model)
└─ Transformer Decoder (cross-attn Memory) → (k, d_model)
└─ Linear → (k, 14) = 액션 청크 â_{t:t+k}
[추론]
z = 0 (prior mean) ← CVAE 인코더 버림
나머지 동일
CVAE: 인간 시연의 다양성을 담는 그릇
ACT는 Conditional VAE 구조를 씁니다. CVAE 인코더는 훈련 시에만 존재하고 추론 시 버립니다:
CVAE 인코더 (훈련 전용):
입력: 관측 + 액션 시퀀스 a_{t:t+k}
→ Transformer Encoder (경량)
→ [CLS] 토큰 → Linear → μ (d_z,), log σ² (d_z,)
→ z ~ N(μ, σ²) (reparameterization trick)
왜 CVAE인가?
인간 시연에는 다중 모드(multimodal) 패턴이 있습니다. 왼손 먼저 집을 수도, 오른손 먼저 집을 수도. 단순 MSE는 두 방법의 평균 예측 → 어느 방법도 아닌 동작.
스타일 변수 z가 "이번 시연은 이런 방식"을 인코딩 → 멀티모달 분포를 자연스럽게 처리.
인간 데이터에서 CVAE 제거 시: 35.3% → 2%. 스크립트 데이터(일관성 있음)에서는 거의 무관.
손실 함수 상세
L_total = L_reconstruct + β · L_KL
── L_reconstruct ──────────────────────────────────
L_reconstruct = (1/k) · Σ_{i=0}^{k-1} |â_i - a_i|₁
• L1 loss (MAE) 사용 — L2보다 우수
• L2는 다중 모드에서 평균값으로 수렴하는 경향 (mode averaging)
• L1은 피크 쪽으로 수렴하는 경향 (mode seeking)
• k=100 스텝 전체에 대해 평균
── L_KL ────────────────────────────────────────────
L_KL = D_KL(N(μ, σ²) || N(0, I))
= (1/2) · Σ (μ² + σ² - log σ² - 1)
• CVAE 인코더가 과도하게 z에 의존하지 않도록 정규화
• β 파라미터: 기본 β=10 (KL 비중 조절)
• β 크면 z 무시 → 추론 시 z=0으로도 잘 동작
• β 작으면 z에 과의존 → 추론 시 성능 저하
── 학습 요약 ─────────────────────────────────────
optimizer: AdamW
lr: 1e-5 (backbone), 1e-4 (나머지)
batch: 8, epochs: 2000 (약 50데모 × 200에포크/데모)
Action Chunking: 오차 누적의 수학적 해결
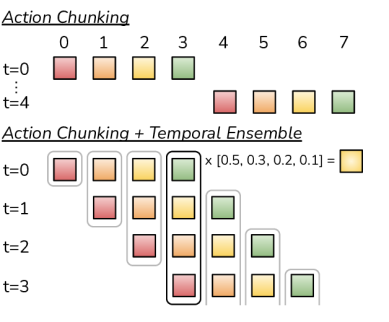 Fig.3. Action Chunking과 Temporal Ensemble 시각화
Fig.3. Action Chunking과 Temporal Ensemble 시각화
핵심 통찰: k스텝을 한 번에 예측하면 유효 호라이즌(effective horizon)이 k배 짧아집니다.
단일 스텝 (k=1): T번 쿼리 → 오차 누적 ∝ e^T
청크 (k=100): T/100번 쿼리 → 오차 누적 ∝ e^(T/100)
Slot Battery 태스크 실험:
| 청크 크기 k | 성공률 |
| 1 | 1% |
| 10 | 26% |
| 50 | 84% |
| 100 | 96% |
k=1 → k=100: 아키텍처 변경 없이 단순히 청크 크기만 키워서 1% → 96%. 이 결과가 Action Chunking의 핵심 증거.
Temporal Ensemble: ACT가 실제로 부드럽게 동작하는 이유
Action Chunking만 있으면 k스텝마다 청크 경계에서 급격한 방향 전환이 발생합니다. Temporal Ensemble이 이를 해결하는 방식이 ACT의 실용성을 결정적으로 높입니다.
동작 방식:
타임스텝 t에서:
→ 새 청크 쿼리: [â_t^(0), â_{t+1}^(0), ..., â_{t+k-1}^(0)]
타임스텝 t+1에서:
→ 또 새 청크 쿼리: [â_{t+1}^(1), â_{t+2}^(1), ..., â_{t+k}^(1)]
타임스텝 t+2에서:
→ 또 새 청크 쿼리: ...
타임스텝 t+1의 실행 액션:
â_{t+1}^(0): w_0 = exp(-m·1) ← 1스텝 전 예측
â_{t+1}^(1): w_1 = exp(-m·0) ← 방금 예측 ← 가중치 최대
→ a_exec = (w_1·â^(1) + w_0·â^(0)) / (w_1 + w_0)
왜 이게 중요한가:
- 노이즈 평균화: 각 추론마다 약간의 예측 변동 → 앙상블이 분산을 줄임
- 최신 관측 반영: 방금 찍은 이미지로 예측한 액션에 최고 가중치 → 외란에 빠르게 반응
- 부드러운 연속성: 인접 타임스텝의 예측이 공유되어 저크(jerk) 감소
결과: 3~4% 성능 향상 + 육안으로 확인 가능한 동작 부드러움. 실제 배포에서 Temporal Ensemble 없는 ACT와 있는 ACT는 영상으로 보면 명확히 다릅니다.
ALOHA 하드웨어 (요약)

ViperX 6-DOF × 2 (팔로워) + WidowX × 2 (리더), 카메라 4개, 총 ~$20,000. 50Hz 관절 위치 제어. 상세 스펙보다 중요한 건 이 플랫폼이 ACT의 공개 재현 기준이 됐다는 점 — 코드·하드웨어 모두 오픈소스로 공개돼 전 세계 연구팀이 동일 세팅에서 비교 실험 가능.
실험 결과
실제 로봇 6개 태스크
 Fig.4. 6개 실제 태스크 — 각각 50개 시연으로 학습
Fig.4. 6개 실제 태스크 — 각각 50개 시연으로 학습
| 태스크 | ACT | BC-ConvMLP | VINN | RT-1 |
| Slide Ziploc | 88% | 0% | 0% | 0% |
| Slot Battery | 96% | 0% | 0% | 0% |
| Open Cup | 84% | 0% | 0% | - |
| Thread Velcro | 20% | 0% | 0% | - |
| Prep Tape | 64% | 0% | 0% | - |
| Put On Shoe | 92% | 20% | 0% | - |
가장 어려운 태스크(Slide Ziploc, Slot Battery)에서 모든 베이스라인이 0%일 때 ACT는 88~96%.
Thread Velcro(벨크로 연결)가 20%로 낮은 이유: 밀리미터 단위 정렬 필요 + 촉각 피드백 없이는 어려운 작업.
시뮬레이션 태스크
| 태스크 | ACT (스크립트) | ACT (인간 데이터) |
| Cube Transfer | 97% | 82% |
| Bimanual Insertion | 90% | 60% |
스크립트(일관된) 데이터 vs 인간(다양한) 데이터 간의 차이가 CVAE의 중요성을 보여줍니다.
Key Experiments
청크 크기 Ablation
가장 인상적인 실험: k=1(단일 스텝) → k=100까지 청크 크기 증가.
Slot Battery 성공률:
k=1 → 1%
k=10 → 26%
k=50 → 84%
k=100 → 96%
이 결과는 오차 누적이 정밀 작업에서 얼마나 치명적인지, 그리고 Action Chunking이 얼마나 강력한 해결책인지를 직접 증명.
CVAE의 필요성
| 설정 | 성공률 |
| ACT 전체 (인간 데이터) | 35.3% (평균) |
| CVAE 없이 (인간 데이터) | 2% |
| ACT 전체 (스크립트 데이터) | 높음 |
| CVAE 없이 (스크립트 데이터) | 거의 동일 |
CVAE는 인간 데이터의 다양성을 처리하는 데 핵심. 균일한 스크립트 데이터에서는 없어도 됨.
제어 주파수 사용자 연구
6명 참가자 대상: 50Hz vs 5Hz 원격조작 비교
- 50Hz가 62% 더 빠른 태스크 완료
- 통계적 유의성 p<0.001
고주파 제어가 정밀 작업에 왜 중요한지를 정량적으로 입증.
Limitations — 현장 엔지니어 관점
알고리즘적 한계:
오픈루프 청크 취약성: π0와 동일한 문제. k=100 스텝을 한 번에 실행하면 중간 외란에 대응 불가. 물체가 예상과 다르게 움직이면 청크 나머지가 모두 틀림
분포 이동에 민감: 훈련 시연과 다른 초기 상태에서 성능 급락. Thread Velcro 20% — 이 작업은 초기 정렬이 조금만 달라도 실패
카메라 의존성: 모든 정책이 4개 카메라 이미지에 의존. 카메라 외란(가림, 반사, 조명 변화)에 취약
태스크별 학습: 각 태스크마다 별도 정책 학습 필요. 하나의 정책이 여러 태스크를 처리하는 범용 정책 아님
현장 관점 추가:
$20,000의 함정: 연구용으로는 저렴하지만 상용화에는 여전히 높은 장벽. 리더 팔도 2개 필요해서 실제 제어 인프라 비용이 더 있음
50개 시연의 편차: "50개 시연으로 96% 성공"은 잘 설계된 특정 태스크에서의 결과. 새 태스크에 적용할 때 몇 개가 필요한지는 작업 난이도에 따라 크게 다름
그리퍼 디자인이 성능을 결정: 논문의 커스텀 그립 테이프 그리퍼가 마찰력을 높여 성공률에 기여. 다른 그리퍼로 교체하면 재조정 필요
청크 크기 k 튜닝: k=100이 Slot Battery에 최적이지만 다른 태스크에서는 다를 수 있음. 작업 시간 길이와 제어 주파수에 맞게 조정 필요
Temporal Ensemble 파라미터 m: 가중치 감쇠 m이 동작 부드러움에 직접 영향. 너무 크면 최신 예측만 사용 (불연속), 너무 작으면 과거 예측이 너무 많이 반영 (지연)
The Lineage — ACT의 계보
| 시스템/논문 | 관계 |
| Behavior Cloning (BC) | 모방학습의 기반, 오차 누적 문제 보유 |
| DAgger (Ross et al. 2011) | BC 오차 누적 해결 시도 — 온라인 수집 필요 |
| Diffusion Policy (Chi et al. 2023) | 동시기 연구, 확산 모델로 멀티모달 행동 처리 |
| GAIL (Ho & Ermon 2016) | GAN 기반 모방학습, 샘플 효율 낮음 |
| ALOHA (Zhao et al. 2023) | ACT의 하드웨어 플랫폼, 동 논문에서 발표 |
| ACT (Zhao et al. 2023) | Action Chunking + CVAE, 현장 정밀 조작의 표준 |
| ACT+ / ACT++ | ACT 후속, 더 다양한 환경에 적용 |
| Mobile ALOHA (He et al. 2024) | ALOHA를 모바일 플랫폼으로 확장, ACT 기반 |
| π0 (Black et al. 2024) | Action Chunking 개념 채용 + Flow Matching으로 확장 |
| ALOHA 2 (Google DeepMind 2024) | ALOHA 하드웨어 개선판 |
ACT가 만든 공식: 저가 하드웨어 + 적은 시연 + Action Chunking = 높은 성공률. 이 공식이 이후 로봇 학습 연구의 중요한 기준이 됩니다.
Summary — Key Takeaways
Action Chunking이 오차 누적을 끊는다 — k스텝을 한 번에 예측하면 유효 호라이즌이 k배 짧아짐. k=1에서 1%, k=100에서 96% — 단순히 청크 크기를 키우는 것만으로 100배 성능 향상
CVAE가 인간 데이터의 다양성을 소화한다 — 스타일 변수 z가 동일 작업의 다양한 시연 방법을 구분. CVAE 없이 인간 데이터 학습: 35% → 2%. 단순 MSE는 멀티모달 분포를 처리 불가
Temporal Ensemble이 청크 경계의 불연속을 해결한다 — 매 스텝 쿼리 + 지수 가중 평균. 3~4% 추가 성능 + 동작 부드러움. 큰 설계 없이 구현 가능한 실용적 트릭
저가 하드웨어 + 50개 시연 = 실용적 정밀 조작 — $20,000 ALOHA + 10분 데이터로 배터리 삽입(96%), 신발 신기(92%). 비싼 하드웨어 없이 연구실·스타트업에서 재현 가능한 수준
Action Chunking은 범용 트릭이다 — BC-ConvMLP와 VINN에 청크를 추가하자 성능이 향상됨을 실험으로 확인. 특정 아키텍처에 종속된 게 아니라 일반적으로 유효한 원칙 — π0, ACT++, 다양한 후속 연구에서 채택
📚 논문: arXiv:2304.13705
🤖 프로젝트: ALOHA 프로젝트 페이지
🐙 코드: GitHub: tonyzhaozh/act
다음 포스트: RPP — 로봇 경로 추적 컨트롤러