ACT: Precision Bimanual Manipulation via Action Chunking — ResNet18, Transformer Decoder & CVAE Deep Dive
Vision encoder to tensor flow, loss function, Temporal Ensemble — the architecture behind 96% success from 50 demos
TL;DR
ACT (Action Chunking with Transformers) is a bimanual robot manipulation imitation learning algorithm from Stanford, published in 2023. Two core ideas: (1) Action Chunking — predict k actions at once rather than one step at a time, reducing compounding errors k-fold; (2) CVAE — capture the multimodal nature of human demonstrations through a style variable z. Built on a $20,000 low-cost bimanual robot (ALOHA), ACT achieves 80–96% success on six precision tasks — battery insertion, shoe fitting, ziploc sealing — from just 50 demonstrations (~10 minutes of data). The foundation for ALOHA 2, Mobile ALOHA, and the action chunking mechanism in π0.
Background: Why Fine-Grained Bimanual Manipulation Is Hard
Inserting a battery in the correct orientation, threading velcro evenly, tying shoelaces — trivial for humans, brutally hard for robots.
Why:
Compounding errors: The classic failure mode of imitation learning. A small error at step t pushes step t+1 outside the training distribution, and errors snowball exponentially.
Multimodal behavior: Humans perform the same task in different ways — left hand first or right hand first, different grip styles. A policy trained with MSE loss predicts the average — which is neither approach, and therefore wrong.
High-frequency precision control: Manipulation at 50 Hz with millimeter-level accuracy. Discrete token autoregression (as in VLAs) can't satisfy this requirement.
Hardware cost barrier: Prior work assumed expensive, highly calibrated manipulators.
Prior approaches and their shortcomings:
| Method | Failure Mode |
| Behavior Cloning (BC) | Compounding errors; 0% on hard tasks |
| RT-1 | Discrete action tokens; poor high-frequency control |
| GAIL/RL | Poor sample efficiency; reward design needed |
| VINN | k-NN retrieval; brittle to novel states |
ACT's answer: Action Chunking + CVAE.
Core Architecture
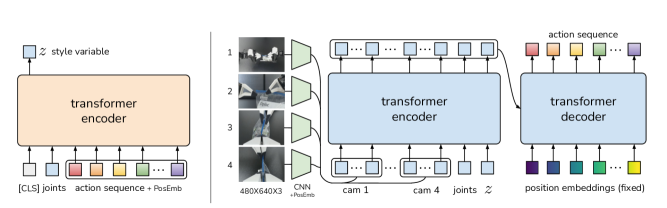 Fig.2. Full ACT architecture — CVAE encoder (training only) + Vision Encoder + Transformer Encoder/Decoder policy
Fig.2. Full ACT architecture — CVAE encoder (training only) + Vision Encoder + Transformer Encoder/Decoder policy
Vision Encoder: ResNet18, Not SigLIP
ACT's vision encoder is ResNet18 (ImageNet pretrained) — a lightweight CNN, not SigLIP or ViT. Chosen specifically for 50 Hz real-time control.
4 cameras (2 static + 2 wrist) → each independently ResNet18-encoded
Input: 480×640 RGB
→ ResNet18 feature extractor
→ Global Average Pooling
→ 512-dim image feature vector per camera
Why ResNet18 and not SigLIP/ViT?
| Encoder | Params | Inference | Use Case |
| ResNet18 | 11M | ~3ms/frame | ACT (50Hz control) |
| ViT-B/16 | 86M | ~15ms/frame | High-level understanding |
| SigLIP-400M | 400M | ~50ms/frame | VLAs (OpenVLA, π0) |
50 Hz = full inference in <20ms. SigLIP takes ~50ms per frame alone — that's already 2.5x the budget. ResNet18 at ~3ms/frame is the only realistic choice for real-time manipulation control.
Transformer Encoder: Multimodal Observation Integration
Vision features, joint state, and style variable are concatenated into a single sequence:
Token sequence:
[z_token] # style variable (1 token)
[joint_token] # 14-dim joint positions → linear projection → d_model
[img_token_0 ... img_token_N] # ResNet18 spatial feature tokens
→ Positional Embedding
→ Transformer Encoder (standard BERT-style)
- Multi-head Self-Attention
- Feed-Forward Network
- Layer Normalization
→ Output: contextualized token sequence (Memory)
The key: self-attention automatically learns which image regions to associate with which joint states — no hand-coded spatial reasoning.
Transformer Decoder: Action Chunk Generation
k learnable query tokens generate the action sequence:
Query tokens: Q_0, Q_1, ..., Q_{k-1} (each d_model dim, randomly initialized → learned)
Transformer Decoder (each layer):
1. Self-Attention(Q_i, Q_j) # queries interact with each other (temporal coherence)
2. Cross-Attention(Q_i, Memory) # inject observation context into queries
3. FFN + LayerNorm
Output: each Q_i → Linear(d_model → 14)
→ â_i = [θ_1, ..., θ_14] # joint positions for timestep i
Full tensor flow:
[Training]
Images (4, 3, 480, 640)
└─ ResNet18 × 4 → (4, 512, H', W') → flatten → (N_vis, 512) → (N_vis, d_model)
Joints (14,) → Linear → (1, d_model)
z (d_z,) → Linear → (1, d_model)
Sequence = concat([z_token, joint_token, img_tokens]) # (2+N_vis, d_model)
└─ Transformer Encoder → Memory (2+N_vis, d_model)
Query tokens (k, d_model)
└─ Transformer Decoder (cross-attn Memory) → (k, d_model)
└─ Linear → (k, 14) = action chunk â_{t:t+k}
[Inference]
z = 0 (prior mean) ← CVAE encoder is discarded
Everything else identical
CVAE: Capturing the Diversity of Human Demonstrations
ACT uses a Conditional VAE structure. The CVAE encoder exists during training only and is discarded at inference:
CVAE Encoder (training only):
Input: observation + action sequence a_{t:t+k}
→ Transformer Encoder (lightweight)
→ [CLS] token → Linear → μ (d_z,), log σ² (d_z,)
→ z ~ N(μ, σ²) (reparameterization trick)
Why CVAE?
Human demonstrations are multimodal — the same task may be done with the left hand first, or the right hand first, with different grip styles. Naive MSE loss predicts the average of all modes — a motion that is literally neither strategy. The style variable z encodes "this demonstration follows this particular mode", allowing the policy to handle multimodal distributions naturally.
Effect on human data: removing the CVAE causes performance to collapse from 35.3% to 2%. With scripted (consistent) data, CVAE has negligible effect — confirming it exists specifically to handle human variability.
Loss Function Details
L_total = L_reconstruct + β · L_KL
── L_reconstruct ──────────────────────────────────
L_reconstruct = (1/k) · Σ_{i=0}^{k-1} |â_i - a_i|₁
• L1 loss (MAE) — outperforms L2
• L2 tends to average across modes (mode averaging → wrong behavior)
• L1 tends toward peaks (mode seeking → picks a real behavior)
• averaged across all k=100 steps
── L_KL ───────────────────────────────────────────
L_KL = D_KL(N(μ, σ²) || N(0, I))
= (1/2) · Σ (μ² + σ² - log σ² - 1)
• Regularizes encoder to not over-rely on z
• β=10 (default) — high value keeps z close to prior N(0,I)
• High β → z ≈ 0 at inference works fine (encoder not needed)
• Low β → z over-encodes specifics → inference breaks without encoder
── Training summary ──────────────────────────────
optimizer: AdamW
lr: 1e-5 (backbone), 1e-4 (rest)
batch: 8, epochs: 2000
Action Chunking: The Mathematical Fix for Compounding Errors
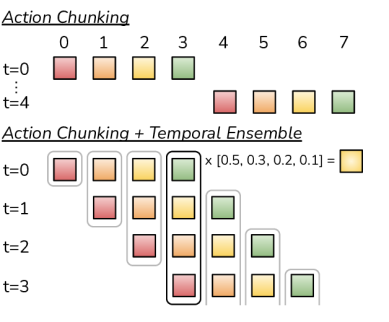 Fig.3. Action Chunking and Temporal Ensemble visualization
Fig.3. Action Chunking and Temporal Ensemble visualization
Core insight: predicting k steps at once reduces the effective horizon by a factor of k.
Single-step prediction (k=1):
T queries, error accumulation ≈ e^T
Chunk prediction (k=100):
T/100 queries, error accumulation ≈ e^(T/100)
Slot Battery task ablation:
| Chunk size k | Success rate |
| 1 (single step) | 1% |
| 10 | 26% |
| 50 | 84% |
| 100 | 96% |
k=1 → k=100: no architecture change, just predict more steps at once, and success rate goes from 1% to 96%. This is the central result of the paper.
Temporal Ensemble: Why ACT Actually Moves Smoothly
Action Chunking alone creates discontinuities at chunk boundaries — every k steps, the policy issues a completely new plan, causing sharp direction changes. Temporal Ensemble solves this and it's what makes ACT practical in deployment.
How it works:
At timestep t:
→ Query new chunk: [â_t^(0), â_{t+1}^(0), ..., â_{t+k-1}^(0)]
At timestep t+1:
→ Query again: [â_{t+1}^(1), â_{t+2}^(1), ..., â_{t+k}^(1)]
At timestep t+1, the executed action:
â_{t+1}^(0): w_0 = exp(-m·1) ← predicted 1 step ago
â_{t+1}^(1): w_1 = exp(-m·0) ← just predicted ← highest weight
→ a_exec = (w_1·â^(1) + w_0·â^(0)) / (w_1 + w_0)
Why this matters:
- Noise averaging: each inference has slight prediction variance → ensemble reduces it
- Fresh observation weighting: the prediction using the latest image gets highest weight → fast response to disturbances
- Smooth continuity: adjacent timesteps share overlapping predictions → jerk reduction
Result: +3–4% performance + visually smoother motion. ACT with and without Temporal Ensemble look distinctly different on video.
ALOHA: A $20,000 Low-Cost Bimanual Platform

ViperX 6-DOF × 2 (follower) + WidowX × 2 (leader), 4 cameras, ~$20,000 total. 50 Hz joint position control. What matters more than the hardware specs: ALOHA became the standard reproducible baseline — code and hardware fully open-sourced, enabling labs worldwide to run identical experiments for direct comparison.
Experimental Results
Six Real-World Tasks
 Fig.4. Six real-world tasks, each learned from 50 demonstrations
Fig.4. Six real-world tasks, each learned from 50 demonstrations
| Task | ACT | BC-ConvMLP | VINN | RT-1 |
| Slide Ziploc | 88% | 0% | 0% | 0% |
| Slot Battery | 96% | 0% | 0% | 0% |
| Open Cup | 84% | 0% | 0% | — |
| Thread Velcro | 20% | 0% | 0% | — |
| Prep Tape | 64% | 0% | 0% | — |
| Put On Shoe | 92% | 20% | 0% | — |
All baselines score 0% on the hardest tasks. ACT achieves 88–96%.
Thread Velcro at 20% — requires millimeter alignment and implicit tactile feedback. Still 20× better than baselines; the limiting factor is precision beyond visual feedback alone.
Simulation Tasks
| Task | ACT (scripted) | ACT (human data) |
| Cube Transfer | 97% | 82% |
| Bimanual Insertion | 90% | 60% |
The gap between scripted and human data quantifies exactly why CVAE matters — human variability is real and must be modeled.
Key Experiments
Chunk Size Ablation
The most compelling result in the paper:
Slot Battery success rate:
k=1 → 1%
k=10 → 26%
k=50 → 84%
k=100 → 96%
Not just an ablation of ACT — the paper also augments BC-ConvMLP and VINN with action chunking, and both improve substantially. This proves action chunking is a general principle, not an ACT-specific trick.
CVAE Necessity
| Configuration | Success Rate |
| Full ACT (human data) | 35.3% avg |
| Without CVAE (human data) | 2% |
| Full ACT (scripted data) | High |
| Without CVAE (scripted data) | ≈ identical |
CVAE matters exactly when demonstrations are diverse. For scripted (deterministic) data, it doesn't help or hurt.
Control Frequency User Study
6 participants, 50 Hz vs 5 Hz teleoperation:
- 50 Hz was 62% faster at task completion
- Statistical significance: p < 0.001
Justifies the 50 Hz design choice and explains why coarser-grained control fails on precision tasks.
Limitations — A Field Engineer's Perspective
Algorithmic limitations:
Open-loop chunk vulnerability: Executing k=100 steps without mid-chunk feedback means any unexpected disturbance (object slip, slight misalignment) invalidates the remaining actions. The model can't react within a chunk.
Distribution shift sensitivity: Tasks like Thread Velcro at 20% show that precision manipulation can be fragile to slight initial condition variations not covered in training.
Camera dependency: All four cameras must be intact, clean, and well-lit. Occlusion, glare, or lighting change degrades performance, with no graceful degradation mechanism.
Per-task policies: Each task requires separate training. ACT is not a generalist policy — it's a specialist trained for one task at a time.
Field engineering perspective:
The $20,000 trap: For research, this is genuinely affordable. For production, $20,000 per robot station plus operator time for 50+ demonstrations per task adds up quickly.
50 demonstrations variance: The 96% on Slot Battery used carefully collected demonstrations in a controlled environment. A new task in a messier real environment may need 200+ to reach the same level.
Gripper design matters more than expected: The custom grip-tape grippers contribute meaningfully to success rates. Swapping to a standard parallel gripper requires re-collection and may not achieve the same results.
Chunk size k tuning: k=100 is optimal for a 50 Hz, ~2 second task. For longer or shorter tasks, k should scale with task duration × control frequency. Environment-specific hyperparameter.
Temporal ensemble parameter m: Too large → recent predictions dominate, behavior becomes jerky at re-query points. Too small → stale predictions linger, adding latency. Requires tuning per platform.
The Lineage — Where ACT Sits
| System / Paper | Relationship |
| Behavior Cloning | Foundation of imitation learning; ACT's starting point |
| DAgger (Ross et al. 2011) | Early fix for BC compounding errors — requires online data collection |
| Diffusion Policy (Chi et al. 2023) | Concurrent work; diffusion for multimodal behavior |
| GAIL (Ho & Ermon 2016) | GAN-based IL; poor sample efficiency |
| ALOHA (Zhao et al. 2023) | ACT's hardware platform; published in the same paper |
| ACT (Zhao et al. 2023) | Action Chunking + CVAE; precision manipulation standard |
| Mobile ALOHA (He et al. 2024) | ALOHA extended to mobile base; ACT as policy |
| ALOHA 2 (Google DeepMind 2024) | Improved ALOHA hardware |
| π0 (Black et al. 2024) | Adopts action chunking concept + extends with Flow Matching |
| ACT+ / ACT++ | Follow-up extensions to more diverse environments |
The formula ACT established: low-cost hardware + few demonstrations + action chunking = high success rate on fine manipulation. This is now a benchmark every subsequent manipulation paper measures against.
Summary — Key Takeaways
Action Chunking breaks the compounding error cycle — predicting k steps at once reduces the effective horizon k-fold. k=1 → 1%, k=100 → 96% on Slot Battery. No architecture change; just predict more steps at once.
CVAE handles the diversity of human demonstrations — style variable z separates different "modes" of the same task. Without CVAE on human data: 35% → 2%. Naive MSE loss on multimodal behavior leads to averaging-induced failure.
Temporal Ensemble resolves inter-chunk discontinuities — query every step, merge with exponential weighted averaging. +3–4% performance, smoother motion. Noise averaging, fresh-observation weighting, and jerk reduction in one simple mechanism.
$20,000 hardware + 50 demonstrations = practical precision manipulation — ALOHA with ~10 minutes of data achieves 96% battery insertion, 92% shoe fitting. A level of accessibility that opened this research direction to many more labs.
Action Chunking is a general principle, not an ACT-specific trick — confirmed by augmenting BC-ConvMLP and VINN with chunking (both improve). π0, ACT++, and many subsequent systems adopted it. Any sequential manipulation policy benefits from predicting multiple steps ahead.
📚 Paper: arXiv:2304.13705
🤖 Project page: ALOHA Project
🐙 Code: GitHub: tonyzhaozh/act
Next post: RPP — Robot path tracking controller